| Bert | 您所在的位置:网站首页 › bertbase bilstm crf › Bert |
Bert
|
引入
Bert-bilistm-crf进行命名体识别其实就是在bilstm-crf的基础上引入bert词向量,pytorch官网给出了的bilstm-crf的模板代码,但是pytorch官方的bilstm-crf的代码存在两个问题: 1. 代码的复杂度过高,可以利用pytorch的广播计算方式,将其复杂度降低。 2.官方代码的batch_size仅仅为1,实际运用时需要将batch_size调大。 对于问题1,知乎上有人重新实现了bilstm-crf的pytorch代码(手撕 BiLSTM-CRF),该段代码可以很好的降低计算的复杂度,并且作者也给出了详细的代码解读,对于初学者建议看看这篇文章,但是这段代码一方面维特比解码这块最后我认为不需要进行log_sum_exp的操作,另一方面仍然存在batch_size为1的问题,因此本文最终使用的其实是github上的代码,该代码可以较好的解决以上两个问题,但是原文使用的是原始的pytorch_pretrained_bert模块,因此需要做相应的修改。本文也是对该代码进行相应的讲解。 官网代码:https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html 知乎(手撕 BiLSTM-CRF): https://zhuanlan.zhihu.com/p/97676647 维特比解码原理解释(该链接的第一个问题的推导有误):https://zhuanlan.zhihu.com/p/97829287 Github(最终使用):https://github.com/HandsomeCao/Bert-BiLSTM-CRF-pytorch 1.原始数据代码中应用到的数据为医药命名体识别数据,已经处理成了BIO格式,其中B、I包含6个种类,分别为DSE(疾病和诊断),DRG(药品),OPS(手术),LAB( 检验),PAT(解剖部位)、INF(检查)。
官网链接:https://www.biendata.xyz/competition/ccks_2019_1/
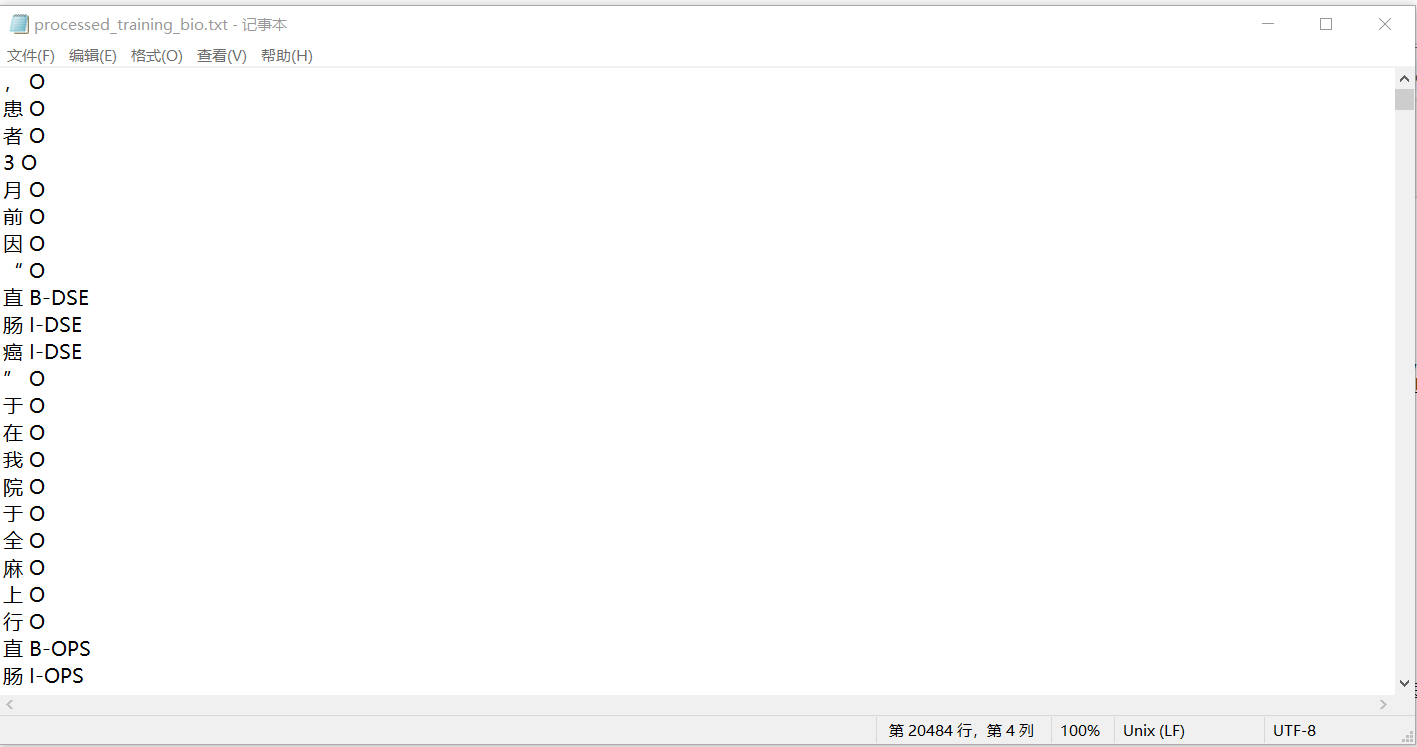
原始数据集的格式如下所示,已经处理成每一行包含一个字及其对应标识。原始数据中包含多个段落,段落与段落之间通过\n\n隔开,而每个段落内可能有多个句子。
首先对数据进行预处理,处理方式通过NerDataset类进行封装。 import os import numpy as np import logging import torch from torch.utils.data import Dataset from typing import Tuple, List from transformers import BertTokenizer logger = logging.getLogger(__name__) bert_model = 'bert-base-chinese' tokenizer = BertTokenizer.from_pretrained(bert_model) # VOCAB = ('', 'O', 'I-LOC', 'B-PER', 'I-PER', 'I-ORG', 'B-LOC', 'B-ORG') VOCAB = ('', '[CLS]', '[SEP]', 'O', 'B-INF', 'I-INF', 'B-PAT', 'I-PAT', 'B-OPS', 'I-OPS', 'B-DSE', 'I-DSE', 'B-DRG', 'I-DRG', 'B-LAB', 'I-LAB') tag2idx = {tag: idx for idx, tag in enumerate(VOCAB)} idx2tag = {idx: tag for idx, tag in enumerate(VOCAB)} MAX_LEN = 256 - 2 class NerDataset(Dataset): def __init__(self, f_path): with open(f_path, 'r', encoding='utf-8') as fr: entries = fr.read().strip().split('\n\n') sents, tags_li = [], [] # list of lists for entry in entries: words = [line.split()[0] for line in entry.splitlines()] tags = ([line.split()[-1] for line in entry.splitlines()]) if len(words) > MAX_LEN: # 先对句号分段 word, tag = [], [] for char, t in zip(words, tags): if char != '。': if char != '\ue236': # 测试集中有这个字符 word.append(char) tag.append(t) else: sents.append(["[CLS]"] + word[:MAX_LEN] + ["[SEP]"]) tags_li.append(['[CLS]'] + tag[:MAX_LEN] + ['[SEP]']) word, tag = [], [] # 最后的末尾 if len(word): sents.append(["[CLS]"] + word[:MAX_LEN] + ["[SEP]"]) tags_li.append(['[CLS]'] + tag[:MAX_LEN] + ['[SEP]']) word, tag = [], [] else: sents.append(["[CLS]"] + words[:MAX_LEN] + ["[SEP]"]) tags_li.append(['[CLS]'] + tags[:MAX_LEN] + ['[SEP]']) self.sents, self.tags_li = sents, tags_li def __getitem__(self, idx): words, tags = self.sents[idx], self.tags_li[idx] x, y = [], [] is_heads = [] for w, t in zip(words, tags): tokens = tokenizer.tokenize(w) if w not in ("[CLS]", "[SEP]") else [w] xx = tokenizer.convert_tokens_to_ids(tokens) # assert len(tokens) == len(xx), f"len(tokens)={len(tokens)}, len(xx)={len(xx)}" # 中文没有英文wordpiece后分成几块的情况 is_head = [1] + [0]*(len(tokens) - 1) t = [t] + [''] * (len(tokens) - 1) yy = [tag2idx[each] for each in t] # (T,) x.extend(xx) is_heads.extend(is_head) y.extend(yy) assert len(x)==len(y)==len(is_heads), f"len(x)={len(x)}, len(y)={len(y)}, len(is_heads)={len(is_heads)}" # seqlen seqlen = len(y) # to string words = " ".join(words) tags = " ".join(tags) return words, x, is_heads, tags, y, seqlen def __len__(self): return len(self.sents) def pad(batch): '''Pads to the longest sample''' f = lambda x: [sample[x] for sample in batch] words = f(0) is_heads = f(2) tags = f(3) seqlens = f(-1) maxlen = np.array(seqlens).max() f = lambda x, seqlen: [sample[x] + [0] * (seqlen - len(sample[x])) for sample in batch] # 0: x = f(1, maxlen) y = f(-2, maxlen) f = torch.LongTensor return words, f(x), is_heads, tags, f(y), seqlens
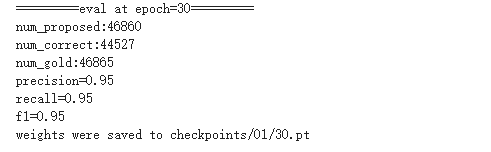
其中__init__函数根据句子最大长度和句号对原始数据进行分割,并在句子首尾补充【cls】、【sep】符号。得到的self.sents和self.tags_li的样例如下: self.sents [['[CLS]', '肠', '壁', '一', '站', '(', '1', '0', '个', ')', '、', '中', '间', '组', '(', '8', '个', ')', '淋', '巴', '结', '未', '查', '见', '癌', '[SEP]'],...]self.tags_li [['[CLS]', 'B-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'I-PAT', 'O', 'O', 'O', 'O', '[SEP]']、...]__getitem__函数的作用是根据self.sents、self.tags_li及相应的索引idx,将数据转换成word、x、is_heads、tags、y、seqlen,其中x、y即为self.sents、self.tags_li中的数据转换对应id的形式,将输入到模型中。 pad函数的作用是在利用DataLoader生成batch数据时,由于每个batch内的各个数据长度不一致,因此pad函数首先求出该batch中数据最大长度,然后对该batch中长度小于最大长度的数据进行padding,最后通过DataLoder将数据喂入模型中。 3.定义模型(crf.py)模型的结构其实和官网给出的模型结构差不多,主要是由于运用到了广播计算的方式,所以有些代码理解起来麻烦一点,并且原始的GitHub代码运用的是pytorch_pretrained_bert模型,改成transformers模块后需要对代码稍作修改,现在直接给出修改后的代码。 ###模型的输入参数的格式为[batch_size, max_seq_len],每个batch的max_seq_len都会不同 import torch import torch.nn as nn from transformers import BertModel def argmax(vec): # return the argmax as a python int _, idx = torch.max(vec, 1) return idx.item() # Compute log sum exp in a numerically stable way for the forward algorithm def log_sum_exp(vec): max_score = vec[0, argmax(vec)] max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) return max_score + \ torch.log(torch.sum(torch.exp(vec - max_score_broadcast))) #对于三维的tensor:[batch_size, 行, 列], #log_sum_exp_batch函数的作用相当于,对于每一个batch,先对每一个元素求e的指数,然后在行的维度上求和 def log_sum_exp_batch(log_Tensor, axis=-1): # shape (batch_size,n,m) return torch.max(log_Tensor, axis)[0] + \ torch.log(torch.exp(log_Tensor-torch.max(log_Tensor, axis)[0].view(log_Tensor.shape[0],-1,1)).sum(axis)) class Bert_BiLSTM_CRF(nn.Module): def __init__(self, tag_to_ix, hidden_dim=768): super(Bert_BiLSTM_CRF, self).__init__() self.tag_to_ix = tag_to_ix self.tagset_size = len(tag_to_ix) # self.hidden = self.init_hidden() self.lstm = nn.LSTM(bidirectional=True, num_layers=2, input_size=768, hidden_size=hidden_dim//2, batch_first=True) self.transitions = nn.Parameter(torch.randn( self.tagset_size, self.tagset_size )) self.hidden_dim = hidden_dim self.start_label_id = self.tag_to_ix['[CLS]'] self.end_label_id = self.tag_to_ix['[SEP]'] self.fc = nn.Linear(hidden_dim, self.tagset_size) self.bert = BertModel.from_pretrained('bert-base-chinese') # self.bert.eval() # 知用来取bert embedding self.transitions.data[self.start_label_id, :] = -10000 self.transitions.data[:, self.end_label_id] = -10000 self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') # self.transitions.to(self.device) def init_hidden(self): return (torch.randn(2, 1, self.hidden_dim // 2), torch.randn(2, 1, self.hidden_dim // 2)) def _forward_alg(self, feats): ''' this also called alpha-recursion or forward recursion, to calculate log_prob of all barX ''' #feats的维度:batch_size*max_seq_length*tagset_size # T = self.max_seq_length T = feats.shape[1] batch_size = feats.shape[0] # alpha_recursion,forward, alpha(zt)=p(zt,bar_x_1:t) log_alpha = torch.Tensor(batch_size, 1, self.tagset_size).fill_(-10000.).to(self.device) #[batch_size, 1, 16] # normal_alpha_0 : alpha[0]=Ot[0]*self.PIs # self.start_label has all of the score. it is log,0 is p=1 log_alpha[:, 0, self.start_label_id] = 0 # feats: sentances -> word embedding -> lstm -> MLP -> feats # feats is the probability of emission, feat.shape=(1,tag_size) for t in range(1, T): log_alpha = (log_sum_exp_batch(self.transitions + log_alpha, axis=-1) + feats[:, t]).unsqueeze(1) # log_prob of all barX log_prob_all_barX = log_sum_exp_batch(log_alpha) return log_prob_all_barX #feats的维度:batch_size*max_seq_length*tagset_size def _score_sentence(self, feats, label_ids): T = feats.shape[1] batch_size = feats.shape[0] batch_transitions = self.transitions.expand(batch_size,self.tagset_size,self.tagset_size) batch_transitions = batch_transitions.flatten(1) score = torch.zeros((feats.shape[0],1)).to(self.device) # the 0th node is start_label->start_word,the probability of them=1. so t begin with 1. for t in range(1, T): score = score + \ batch_transitions.gather(-1, (label_ids[:, t]*self.tagset_size+label_ids[:, t-1]).view(-1,1)) \ + feats[:, t].gather(-1, label_ids[:, t].view(-1,1)).view(-1,1) return score def _bert_enc(self, x): """ x: [batchsize, sent_len] enc: [batch_size, sent_len, 768] """ with torch.no_grad(): encoded_layer = self.bert(x) enc = encoded_layer[0] return enc def _viterbi_decode(self, feats): ''' Max-Product Algorithm or viterbi algorithm, argmax(p(z_0:t|x_0:t)) ''' # T = self.max_seq_length T = feats.shape[1] batch_size = feats.shape[0] # batch_transitions=self.transitions.expand(batch_size,self.tagset_size,self.tagset_size) log_delta = torch.Tensor(batch_size, 1, self.tagset_size).fill_(-10000.).to(self.device) log_delta[:, 0, self.start_label_id] = 0. # psi is for the vaule of the last latent that make P(this_latent) maximum. psi = torch.zeros((batch_size, T, self.tagset_size), dtype=torch.long) # psi[0]=0000 useless for t in range(1, T): # delta[t][k]=max_z1:t-1( p(x1,x2,...,xt,z1,z2,...,zt-1,zt=k|theta) ) # delta[t] is the max prob of the path from z_t-1 to z_t[k] log_delta, psi[:, t] = torch.max(self.transitions + log_delta, -1) # psi[t][k]=argmax_z1:t-1( p(x1,x2,...,xt,z1,z2,...,zt-1,zt=k|theta) ) # psi[t][k] is the path choosed from z_t-1 to z_t[k],the value is the z_state(is k) index of z_t-1 log_delta = (log_delta + feats[:, t]).unsqueeze(1) # trace back path = torch.zeros((batch_size, T), dtype=torch.long) # max p(z1:t,all_x|theta) max_logLL_allz_allx, path[:, -1] = torch.max(log_delta.squeeze(), -1) for t in range(T-2, -1, -1): # choose the state of z_t according the state choosed of z_t+1. path[:, t] = psi[:, t+1].gather(-1,path[:, t+1].view(-1,1)).squeeze() return max_logLL_allz_allx, path def neg_log_likelihood(self, sentence, tags): feats = self._get_lstm_features(sentence) #[batch_size, max_len, 16] forward_score = self._forward_alg(feats) gold_score = self._score_sentence(feats, tags) return torch.mean(forward_score - gold_score) def _get_lstm_features(self, sentence): """sentence is the ids""" # self.hidden = self.init_hidden() embeds = self._bert_enc(sentence) # enc: [batch_size, sent_len, 768] # 过lstm enc, _ = self.lstm(embeds) lstm_feats = self.fc(enc) return lstm_feats # [[batch_size, sent_len, target_size] def forward(self, sentence): # dont confuse this with _forward_alg above. # Get the emission scores from the BiLSTM lstm_feats = self._get_lstm_features(sentence) # [8, 180,768] # Find the best path, given the features. score, tag_seq = self._viterbi_decode(lstm_feats) return score, tag_seq 4.训练与评估(main.py)最后定义训练和评估函数,并定义训练集和测试集的迭代器,总共训练30个epoch,每一个epoch结束后都用测试集进行测试。最终效果f1值可以达到0.95。 现在直接附上代码: # -*- encoding: utf-8 -*- import torch import torch.nn as nn import torch.optim as optim import os import numpy as np import argparse from torch.utils import data from model import Net from crf import Bert_BiLSTM_CRF from utils import NerDataset, pad, VOCAB, tokenizer, tag2idx, idx2tag os.environ['CUDA_VISIBLE_DEVICES'] = '1' def train(model, iterator, optimizer, criterion, device): model.train() for i, batch in enumerate(iterator): words, x, is_heads, tags, y, seqlens = batch x = x.to(device) y = y.to(device) _y = y # for monitoring optimizer.zero_grad() loss = model.neg_log_likelihood(x, y) # logits: (N, T, VOCAB), y: (N, T) # logits = logits.view(-1, logits.shape[-1]) # (N*T, VOCAB) # y = y.view(-1) # (N*T,) # writer.add_scalar('data/loss', loss.item(), ) # loss = criterion(logits, y) loss.backward() optimizer.step() if i==0: print("=====sanity check======") #print("words:", words[0]) print("x:", x.cpu().numpy()[0][:seqlens[0]]) # print("tokens:", tokenizer.convert_ids_to_tokens(x.cpu().numpy()[0])[:seqlens[0]]) print("is_heads:", is_heads[0]) print("y:", _y.cpu().numpy()[0][:seqlens[0]]) print("tags:", tags[0]) print("seqlen:", seqlens[0]) print("=======================") if i%10==0: # monitoring print(f"step: {i}, loss: {loss.item()}") def eval(model, iterator, f, device): model.eval() Words, Is_heads, Tags, Y, Y_hat = [], [], [], [], [] with torch.no_grad(): for i, batch in enumerate(iterator): words, x, is_heads, tags, y, seqlens = batch x = x.to(device) # y = y.to(device) _, y_hat = model(x) # y_hat: (N, T) Words.extend(words) Is_heads.extend(is_heads) Tags.extend(tags) Y.extend(y.numpy().tolist()) Y_hat.extend(y_hat.cpu().numpy().tolist()) ## gets results and save with open("temp", 'w', encoding='utf-8') as fout: for words, is_heads, tags, y_hat in zip(Words, Is_heads, Tags, Y_hat): y_hat = [hat for head, hat in zip(is_heads, y_hat) if head == 1] preds = [idx2tag[hat] for hat in y_hat] assert len(preds)==len(words.split())==len(tags.split()) for w, t, p in zip(words.split()[1:-1], tags.split()[1:-1], preds[1:-1]): fout.write(f"{w} {t} {p}\n") fout.write("\n") ## calc metric y_true = np.array([tag2idx[line.split()[1]] for line in open("temp", 'r', encoding='utf-8').read().splitlines() if len(line) > 0]) y_pred = np.array([tag2idx[line.split()[2]] for line in open("temp", 'r', encoding='utf-8').read().splitlines() if len(line) > 0]) num_proposed = len(y_pred[y_pred>1]) num_correct = (np.logical_and(y_true==y_pred, y_true>1)).astype(np.int).sum() num_gold = len(y_true[y_true>1]) print(f"num_proposed:{num_proposed}") print(f"num_correct:{num_correct}") print(f"num_gold:{num_gold}") try: precision = num_correct / num_proposed except ZeroDivisionError: precision = 1.0 try: recall = num_correct / num_gold except ZeroDivisionError: recall = 1.0 try: f1 = 2*precision*recall / (precision + recall) except ZeroDivisionError: if precision*recall==0: f1=1.0 else: f1=0 final = f + ".P%.2f_R%.2f_F%.2f" %(precision, recall, f1) with open(final, 'w', encoding='utf-8') as fout: result = open("temp", "r", encoding='utf-8').read() fout.write(f"{result}\n") fout.write(f"precision={precision}\n") fout.write(f"recall={recall}\n") fout.write(f"f1={f1}\n") os.remove("temp") print("precision=%.2f"%precision) print("recall=%.2f"%recall) print("f1=%.2f"%f1) return precision, recall, f1 if __name__=="__main__": parser = argparse.ArgumentParser() parser.add_argument("--batch_size", type=int, default=128) parser.add_argument("--lr", type=float, default=0.0001) parser.add_argument("--n_epochs", type=int, default=30) parser.add_argument("--finetuning", dest="finetuning", action="store_true") parser.add_argument("--top_rnns", dest="top_rnns", action="store_true") parser.add_argument("--logdir", type=str, default="checkpoints/01") parser.add_argument("--trainset", type=str, default="processed/processed_training_bio.txt") parser.add_argument("--validset", type=str, default="processed/processed_dev_bio.txt") hp = parser.parse_args(args=[]) device = 'cuda' if torch.cuda.is_available() else 'cpu' model = Bert_BiLSTM_CRF(tag2idx).cuda() print('Initial model Done') # model = nn.DataParallel(model) train_dataset = NerDataset(hp.trainset) eval_dataset = NerDataset(hp.validset) print('Load Data Done') train_iter = data.DataLoader(dataset=train_dataset, batch_size=hp.batch_size, shuffle=True, num_workers=4, collate_fn=pad) eval_iter = data.DataLoader(dataset=eval_dataset, batch_size=hp.batch_size, shuffle=False, num_workers=4, collate_fn=pad) optimizer = optim.Adam(model.parameters(), lr = hp.lr) criterion = nn.CrossEntropyLoss(ignore_index=0) print('Start Train...,') for epoch in range(1, hp.n_epochs+1): # 每个epoch对dev集进行测试 train(model, train_iter, optimizer, criterion, device) print(f"=========eval at epoch={epoch}=========") if not os.path.exists(hp.logdir): os.makedirs(hp.logdir) fname = os.path.join(hp.logdir, str(epoch)) precision, recall, f1 = eval(model, eval_iter, fname, device) torch.save(model.state_dict(), f"{fname}.pt") print(f"weights were saved to {fname}.pt")最终结果:
Github地址上还包含人名、地名、机构名的训练和测试数据,运用上文提到的模型进行训练,约10个epoch就能在测试集上达到0.98的f1值。 |

【本文地址】